
This week, Graphcore Co-Founder and CEO Nigel Toon introduced us to the latest product offerings from Graphcore: the GC200 IPU, IPU-Machine M2000 and IPU-POD64. You can view the in-depth video on YouTube right here. As a reseller and a cloud provider of Graphcore IPU servers and instances, we thought we would lay out the key messages for those of you who wants to easily digest the exciting news that was announced. Just click on the individual headers below to jump through the video and review the information.
Compute (GC200 IPU)
Nigel starts off the presentation with compute by introducing the company's GC200 IPU processor. The GC200 is a 7nm processor with 59.4 billion transistors. That is more transistors than any other process die. Additionally, it contains 900MB of on-chip memory (up from 300MB on the MK1) and 1,472 cores (up from 1216 cores on the MK1), capable of executing 8,832 parallel computing threads. This means that the new MK2 IPU systems can deliver up to 8x the performance over the previous Graphcore MK1 IPU systems. That's a significant improvement for those working with applications in NLP or Financial Services.
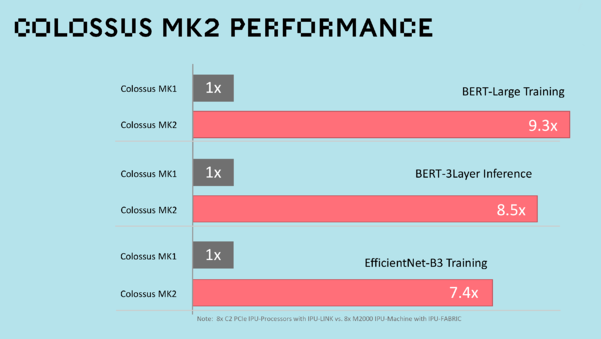
The best news is that users of the Graphcore MK1 IPU products can be assured that their existing models and systems will run seamlessly on these new MK2 IPU systems but will deliver an incredible 8X step up in performance.
Data (Exchange-Memory™)
In addition to the ultra-high bandwidth memory inside the IPU, Graphcore systems now have access to large amount of streaming off-chip memory. Hundreds of gigabytes are now available right next to the IPU processors to hold the largest of models. Up to 450GB of memory density with a data bandwidth of up to 180TB/second is now available with Exchange-Memory™. That bandwidth represents a more than 100x the speed of the latest 7nm GPU-based systems with 10x the density.
Communication (IPU-Fabric™)
At this point, Nigel turns it over to Ola Torudbakken, the SVP of Systems Engineering in Oslo, Norway to talk about Communication and the introduction of Graphcore IPU-Fabric™. The new IPU-Fabric was designed from the ground-up for Machine Intelligence communication and delivers a dedicated low latency fabric that connects IPUs across the entire data center. This is what enables Cirrascale Cloud Services to be able to offer massively scalable cloud instances of up to 1024 Graphcore IPUs (currently in preview), and soon up to 64,000 IPUs.
IPU-Machine M2000
The M2000 is a 1U rackmount server, capable of one PetaFlop of AI compute, powered by 4x GC200 IPU processors. Exchange-Memory extends the GC200's on-chip memory with off-processor Streaming Memory, up to 450GB. The server also includes on-board networking via the IPU-Gateway.

With the M2000 and the IPU-Gateway, all of the networking is included in the server. Just slide it into a rack, connect it to your data center fabric and then connect up the IPU-Fabric links and you're ready to go.
IPU-POD64
Next, Nigel explains that you can connect multiple machines together to create IPU-PODs. IPU-PODs are multi-IPU-Machine scale-out solution for data centers with large AI compute needs. Connect thousands of machines for large Machine Intelligence problems, or multiple, concurrent workloads. Featuring ultra-high bandwidth, low-latency communication, enabled by Graphcore's breakthrough IPU-Fabric technology.

Cirrascale Cloud Services is currently the only cloud services provider offering IPU-POD technology in the cloud. The GRAPHCLOUD offering is currently available under preview and will be officially launch in Q4 2020. GRAPHCLOUD offers customers the ability to scale their application across 64 to 1,024 Graphcore IPUs. Customers interested in previewing GRAPHCLOUD can visit http://graphcloud.ai and sign up.
POPLAR Software Stack
Whether you are using a single IPU or thousands for your Machine Intelligence workload, Graphcore’s Poplar SDK makes this simple. You can use your preferred AI framework, such as TensorFlow or PyTorch, and from this high-level description, Poplar will build the complete compute graph, capturing the computation, the data and the communication. It then compiles this compute graph and builds the runtime programs that manage the compute, the memory management and the networking communication, to take full advantage of the available IPU hardware.
Conclusion
Overall, a lot of great information recapped about the servers and POD technology. You can also visit the Graphcore blog post that goes over the latest releases in great detail as well. If you are interested in learning more about the GRAPHCLOUD PREVIEW from Cirrascale Cloud Services, please visit us at http://graphcloud.ai.