
Apples-to-apples comparisons of AI accelerators are hard to find. But recently both NVIDIA and Graphcore have posted results for pre-training BERT* to convergence, allowing us to compare their performance.
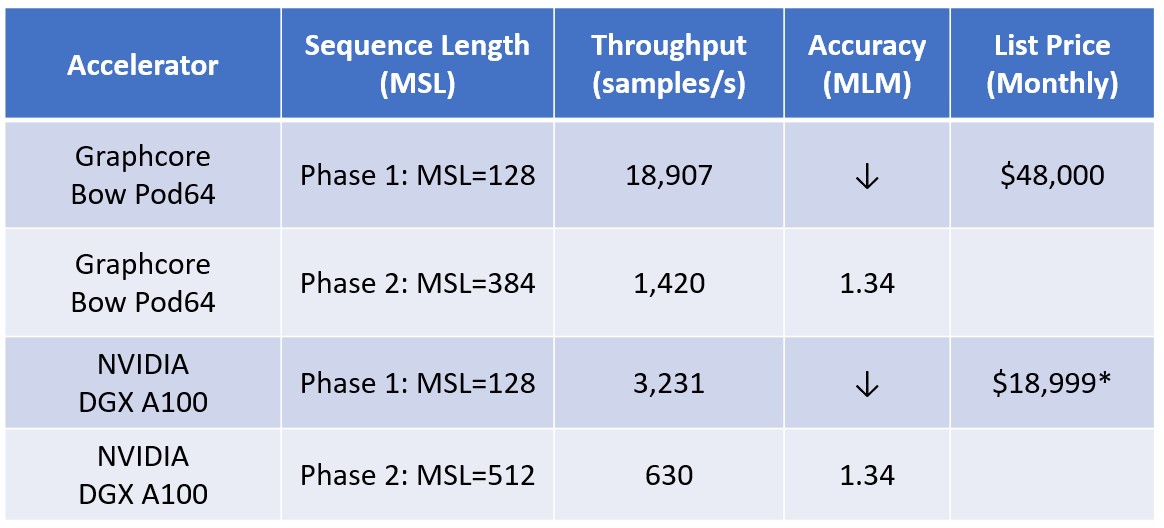
NVIDIA recently reported that their DGX A100 reached 3,231 sequences per second using a maximum sequence length (MSL) of 128. Graphcore published results using their newly released Bow IPU (Intelligence Processing Unit) in a Bow Pod16 configuration. The Bow Pod16 processed 5,179 sequences per second, besting the DGX A100 by 60%! Both Graphcore and NVIDIA went on to train BERT Large to an MLM accuracy of 1.34 using 384 and 512 MSLs, respectively.
Graphcore's results are even more impressive when considering the price. DGX A100 systems are hard to find in the cloud, so let's use a more readily available and lower cost system based on NVIDIA's HGX A100 for comparison. That system costs $18,999 per month using the Cirrascale Cloud Platform, resulting in 472K sequences per dollar. Graphcore's Bow Pod16 costs $12,000 per month using the Cirrascale Cloud Platform, resulting in a throughput of 1.1M sequences per dollar. That's 2.4 times the number of sequences per dollar.
Graphcore's performance advantage does not end there. Packing the dataset before training, which combines multiple smaller sequences into a 128- or 384-bit sequence length, can improve throughput by another 20% or 100%, respectively.
Graphcore has really raised the bar on BERT Large pre-training. I cannot wait to see how NVIDIA responds at GTC 2022 this week. Let us know what you think and leave a comment below.
------------------------------------------------------*References
https://developer.nvidia.com/deep-learning-performance-training-inference
https://www.graphcore.ai/performance-results