
Today, deep learning is at the forefront of powering new technologies used in intelligent cloud-based applications such as autonomous vehicles and natural language recognition. To make decisions and learn from data, a computer model is trained to classify data such as images, text, or sound using large sets of labeled data and neural network architectures that learn features directly from the data. These various deep learning applications process large amounts of data at high speeds, and since funds are never unlimited, companies are typically focused on achieving the lowest price-performance ratio possible.
At Cirrascale Cloud Services, we provide dedicated, multi-GPU cloud solutions to enable these deep learning applications and high-performance computing workloads. Oftentimes, when a client approaches us, they are vastly familiar with the capabilities offered by market-leading Intel® CPUs and assume that an Intel processor will naturally be the best fit for their multi-GPU cloud solution. However, since we are constantly exploring and testing new computing options, and always focused on achieving the best price-performance with our services, we’ve seen that there are now options from AMD that can achieve similar or better price-performance for many multi-GPU deep learning applications.
But, we also know it’s not easy to convince someone to trust a new solution. While we can explain manufacturer specs and pricing, we understand that it is better to share the data we’ve uncovered in our labs through benchmark testing.
Experimental Setup
For our benchmark testing, we trained an Inception V3 model in Tensorflow. We conducted 10 trials of a 500-step training session using multi-GPU systems based on the NVIDIA® Volta® GPU architecture equipped either with dual Intel® Xeon® CPUs or a single AMD EPYC® CPU. Additionally, we used ImageNet data with an image batch size of 64. For the first 20 steps, the images per second processed are not counted towards the current trial training time average since this is the burn-in phase. Additionally, we flushed RAM between each trial since OS caching can cache images in RAM, which can accelerate subsequent tests slightly. Figure 1 below provides more details on the setup of the systems we used.
| System | CPU Model | # CPUS | GPU Model | Interconnect | # GPUs |
| Intel System | Xeon Gold 6148 | 2 | NVIDIA V100 | PCIe | 8 |
| AMD System | EPYC 7401P | 1 | NVIDIA V100 | PCIe | 8 |
Figure 1. System information for the different configurations we used in our benchmark testing for both the Intel and AMD systems.
For each system, we repeated this same benchmark test with mixed mode, which is a feature that is part of the NVIDIA Pascal and Volta architectures enabling data to be stored as FP32 but processed using FP16. Using mixed mode on Volta can increase performance by approximately 50 percent versus traditional methods. This is achieved thanks to Tensor Cores, which is a new feature introduced with Volta architecture, that speeds up FP16 calculations tremendously.
We then calculated the average images processed per second for the 500-step test using the following formula:
GPUs x Batch Size x Training Steps After Burn-in Phase / Time Elapsed After Burn-in Phase
Finally, we averaged the 10 trial results to obtain an “Overall Average” for a system.
Results: Achieving the Best Price-Performance
We were able to demonstrate that a single AMD EPYC CPU offers better performance than a dual CPU Intel-based system.
As shown in Figure 2 below, our testing debunked the myth that AMD processors are typically a bottleneck when used in the deep learning space. The tests demonstrated that a Volta-based GPU system equipped with a single AMD EPYC CPU consistently outperformed a system with two Intel CPUs. Moreover, each Intel Xeon 6148 CPU cost 50% more than the AMD EPYC 7401P CPU.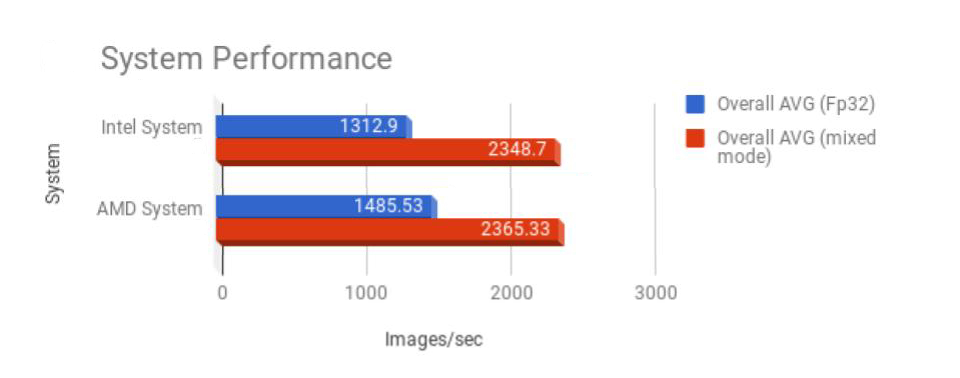 Figure 2. The overall average number of images processed per second for FP32 and mixed mode training using various AMD or Intel CPU-based systems.
Figure 2. The overall average number of images processed per second for FP32 and mixed mode training using various AMD or Intel CPU-based systems.
Another important factor we looked at during our testing is the fact that a single AMD CPU has significantly more PCIe lanes than a single Intel CPU. For example, as shown in Figure 3 below, an AMD EPYC 7351P has 128 PCIe lanes while the Intel E5-2683 v4 has just 40 PCIe lanes. This is important because PCIe lanes are used to connect GPUs, storage, and networking devices to the CPU. Thus, if there are less PCIe lanes available, data transfer will happen at a slower rate or additional CPUs will be needed.
| CPU Model | Price Per CPU* | # of Cores | # of PCIe Lanes | TDP |
| Xeon Gold 6148 | $3,190 | 20 | 48 | 150 |
| EPYC 7401P | $2,048 | 24 | 128 | 155 |
Figure 3. Information on the price, number of cores, number of PCIe lanes, and power usage for the AMD and Intel CPUs. *All pricing shown is estimated.
It is also key to note that in this example, even if two Intel CPUs were used, there are still fewer PCIe lanes available than with one AMD EPYC CPU. Additionally, an argument can be made that adding another Intel CPU doubles the number of cores available, which could accelerate processing, but we concluded that this would likely not be the case. During our testing, we observed CPU utilization of around 10 percent since nearly all the work during training is executed on the GPUs, making the extra cores redundant and not necessary. Since we were only using a single AMD EPYC CPU in this example, the system is using less power than a dual-processor Intel solution, saving money on electricity as well.
Finally, the AMD EPYC is priced lower than an Intel CPU core-for-core. For example, comparing the above CPU models, the EPYC 7401P is priced at around $85 per core while the Intel Xeon Gold 6148 is priced at $159 per core. Thus, during this testing, for nearly half the price, we are experiencing almost the same performance, giving the AMD EPYC much better price-performance than the Intel processor as shown in Figure 4. 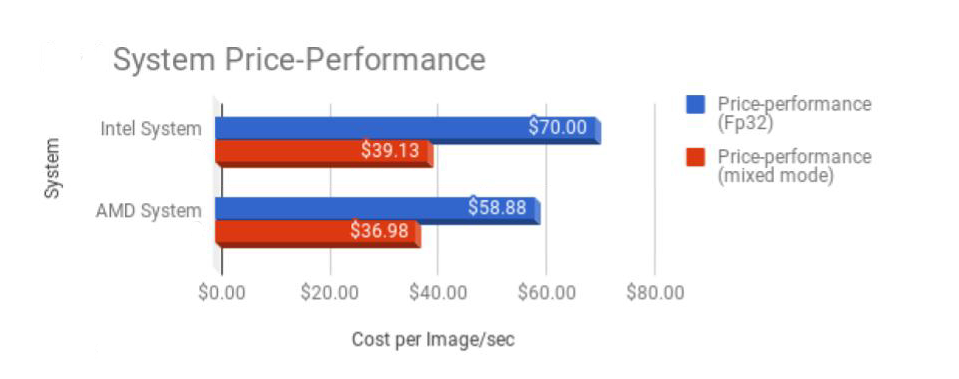 Figure 4. In each test we conducted, the price-performance of the systems using AMD processors was consistently better than the systems using Intel processors.
Figure 4. In each test we conducted, the price-performance of the systems using AMD processors was consistently better than the systems using Intel processors.
In general, through our benchmark testing, we found that using an AMD EPYC CPU as a host for our GPU servers is faster, less expensive, and uses less power on a single socket over a dual socket Intel CPU.
Currently, Cirrascale provides both Intel and AMD architectures in our cloud, and we admittingly use Intel as our current de facto standard in our cloud-based deep learning systems. However, due to the above results and many conversations with our customers, we have begun deploying more AMD EPYC solutions to help reduce costs and improve overall performance.
Ready to get started using AMD EPYC processors for your deep learning applications?
